


1. Grandes dados
A quarta revolução industrial foi iniciada pela digitalização. A digitalização significa a transferência de muitos aspectos da vida humana do mundo real para o virtual, bem como o desenvolvimento de infra-estruturas electrónicas que tornam isso possível. À medida que a digitalização avança, também avançam os métodos de interação humana com computadores e dispositivos eletrónicos. Hoje em dia é difícil funcionar sem pelo menos conhecimentos básicos de Internet e do uso de dispositivos eletrônicos.
As seguintes atividades são realizadas via Internet e via computadores e celulares, entre outras: contatos interpessoais (e-mails, ligações telefônicas, mensagens de texto, mms, chats, fóruns de discussão), compras, operações financeiras, muitas pessoas realizam parte ou todo o seu trabalho profissional utilizando computadores e muitas vezes a Internet, os processos de tomada de decisão nas empresas e outras instituições são também frequentemente realizados através de comunicação remota e reuniões virtuais. A Internet atingiu muito mais profundamente a vida humana, porque muitas pessoas mantêm seus blogs pessoais na Internet e muitas pessoas usam sites de namoro online. Não só os computadores, mas também os eletrodomésticos estão cada vez mais ligados à Internet, pelo que pode, entre outros: verificar o estado do frigorífico durante as compras (alguns frigoríficos podem gerar uma lista de compras para um determinado utilizador), ou controlar e supervisionar o funcionamento de uma máquina de lavar ou de ar condicionado (ou aquecimento central). A informatização chegou a tal ponto que hoje em dia, para reparar um automóvel, na maioria dos casos é necessário primeiro ligar o seu computador de bordo ao computador do mecânico para ler potenciais mensagens de erro e avisos (tomada de diagnóstico). Até as televisões são hoje pequenos computadores que também estão conectados à Internet, para que os usuários possam assistir a filmes em portais online. Isto leva a uma conclusão importante – nomeadamente, que quase todas as pessoas deixam enormes quantidades de dados na Internet. Não apenas pessoas, mas também empresas e quaisquer organizações ou instituições.


Você pode conhecer cada pessoa e instituição na Internet quando nasceram ou quando determinada instituição foi criada, sobre sua localização, muitas vezes você pode encontrar opiniões diferentes em fóruns de discussão, no caso de empresas, seus relatórios financeiros, extratos dos membros do conselho de administração, recomendações, preferências e comportamentos em diversas situações. Nem todos os dados estão disponíveis publicamente, porque alguns dados são confidenciais e privados, mas mesmo com base em dados públicos é possível aprender muito sobre uma pessoa ou uma empresa. As instituições judiciárias, aliás, também têm acesso a dados confidenciais, desde que tal acesso lhes seja concedido por decisão judicial em investigações em andamento.
Também dentro das empresas e instituições, os dados são recolhidos em formato eletrónico, que antes só estava disponível em papel. Cada tarefa recebe seu número de identificação e ao passar pelas pessoas subsequentes que realizam atividades relacionadas a ela, é possível acompanhar seu andamento entre as estações, bem como seu tempo e custos. Todas as transações que são realizadas, por exemplo, em bolsa (transações efetuadas e encomendas efetuadas) também são registadas e depois arquivadas. Até mesmo a forma como o cliente navega no site da loja também fica registrada para verificar quais páginas o cliente visitou, quais produtos ele visualizou, se adicionou produtos ao carrinho ou realizou alguma compra. Cada loja ou empresa coleta informações eletrônicas sobre quantos produtos foram produzidos ou adquiridos, quantos foram vendidos e quais entregas são necessárias para o dia seguinte.
Desta forma, são recolhidas enormes quantidades de dados, chamados big data em inglês, que por vezes é traduzido para polaco como grandes conjuntos de dados. Por um lado, estes dados são extremamente valiosos porque por vezes contêm informações valiosas que permitem tomar decisões corretas no futuro. Por outro lado, a quantidade destes dados é enorme e é necessário utilizar ferramentas adequadas para processar uma quantidade tão grande de dados. Por exemplo, o popular programa Ms Excel permite usar planilhas com um milhão de linhas. Mas se alguém tentasse calcular taxas de retorno para um milhão de observações neste programa, levaria muito tempo – apenas carregar tal arquivo levaria muito tempo. Normalmente, o big data é processado primeiro em programas de banco de dados e depois em programas ou ferramentas estatísticas dedicadas ao big data.
2. Aprendizado de máquina e inteligência artificial como ferramentas para processamento de grandes conjuntos de dados
Uma das ferramentas para processar grandes conjuntos de dados são os algoritmos de aprendizado de máquina e inteligência artificial. A característica comum desses métodos é a busca por padrões e geralmente também a lembrança desses padrões para poder encontrá-los posteriormente em um novo lote de dados. Esses métodos podem ser divididos entre aqueles que buscam padrões por si próprios (sem supervisão humana ou feedback) e aqueles que são aprendidos primeiro, ou seja, são apresentados dados e informados sobre a ocorrência ou não de um padrão específico.
Os métodos que não requerem supervisão incluem: Algoritmo k-NN, ou seja, o algoritmo de busca do vizinho mais próximo. Cada observação – pode ser, por exemplo, o relatório financeiro de uma empresa selecionada – é salva como um vetor multidimensional, ou seja, uma sequência de números (que descreve todos os elementos do relatório financeiro por sua vez). O humano informa ao algoritmo quantos grupos separados existem na população (por exemplo, empresas falidas e aquelas em boa situação financeira). Utilizando várias medidas de distância, o algoritmo agrupará todas as empresas em dois grupos, que, de acordo com a medida de distância selecionada, são semelhantes entre si dentro dos grupos e diferentes entre os grupos. Uma pessoa pode então avaliar se tal divisão faz sentido e é útil.
Os métodos populares que requerem supervisão humana incluem árvores de decisão, método de vetores de suporte, inferência bayesiana ingênua, análise discriminante e redes neurais artificiais. Os algoritmos mencionados baseiam-se em diferentes aparatos matemáticos, mas têm uma coisa em comum. Primeiro vem o processo de aprendizagem. O treinamento cria pares que consistem em um objeto de treinamento de entrada (geralmente um vetor) e uma resposta desejada (geralmente um número). Os algoritmos então processam esses pares de dados e ajustam sua estrutura interna para que sejam capazes de gerar a resposta desejada pelo supervisor com base no objeto de treinamento. Então você pode usar esses algoritmos aprendidos para novos dados com uma resposta desconhecida, e os algoritmos adicionarão a cada novo vetor de dados qual é a resposta para esse vetor de dados. Por exemplo, você poderia apresentar um conjunto específico de demonstrações financeiras de empresas que cometeram crimes financeiros (falsificação de relatórios, suborno, roubo de patentes, etc.) com a informação de que se trata de empresas fraudulentas e, em seguida, algoritmos para os novos dados identificarão ainda mais empresas que provavelmente também cometeram fraude.
Cada algoritmo usa métodos diferentes para aprender como gerar a resposta correta. No caso das árvores de decisão, para todas as informações disponíveis sobre os objetos, é testada qual variável do objeto de treinamento de entrada (no caso das demonstrações financeiras, qual elemento da demonstração financeira) está mais fortemente associada à resposta desejada. Por exemplo, se estiver à procura de fraudadores, poderá descobrir que isso é mais visível nos accruals, que a maioria das empresas fraudadoras tinham accruals invulgarmente elevados, enquanto as entidades honestas os tinham muito mais baixos. É criado o primeiro nó da árvore, que divide as observações em dois grupos para um determinado valor desses assentamentos (ou participação no patrimônio desses assentamentos). Em seguida, busca-se outro elemento do objeto de treinamento, que também distinga claramente entre spawns honestos e desonestos. Desta forma, é construída uma árvore de decisão. A construção de uma árvore geralmente termina quando não há mais candidatos para nós, ou quando a árvore separou corretamente as empresas em honestas e desonestas. A árvore de decisão dividirá o grupo de treinamento em vários subconjuntos, mas cada um desses subconjuntos deverá conter quase exclusivamente fraudadores ou quase exclusivamente empresas honestas.
Em vez de uma árvore de decisão, você pode construir uma floresta inteira. Isso é feito de tal forma que, tendo vetores que descrevem as observações, são selecionadas uma determinada parte das observações e uma determinada parte dos elementos que constituem esses vetores. Como resultado, uma árvore diferente é criada para cada sorteio. Cada árvore foi treinada com menos dados de treinamento do que toda a amostra. Cada árvore tomará então a sua própria decisão sobre se o indivíduo é um impostor ou não, e a decisão final será baseada na votação por maioria. Este método é chamado de floresta aleatória.
Outra variante de uma estrutura baseada em árvore de decisão mais complicada é o algoritmo de aumento de gradiente. Neste caso, a primeira árvore é criada primeiro, com um número limitado de nós. Em seguida, são testadas quais observações a árvore classifica incorretamente. Uma vez que sabemos em quais observações a árvore comete erros, outra árvore é criada para classificar corretamente as observações que a primeira árvore não conseguiu lidar. Então, a terceira árvore e a próxima são criadas usando o mesmo princípio. Depois de treinar o algoritmo e utilizá-lo em novos dados, primeiro a primeira árvore (classificação) gera a resposta, depois a segunda, etc. A primeira árvore “sabe” para quais observações deve se basear na resposta obtida na segunda árvore, e a segunda árvore sabe quando confiar na resposta obtida na terceira árvore.
Além das árvores de decisão, um algoritmo popular é o método da máquina de vetores de suporte (SVM). Neste caso, os objetos de treinamento são novamente vetores de dados. Tais vetores de dados podem ser imaginados como vetores em um espaço multidimensional. A essência do algoritmo SVM é encontrar um hiperplano que divida o espaço multidimensional em duas partes (ou mais partes, dependendo do problema). Isto significa que de um lado do hiperplano deverão existir vetores que descrevam empresas honestas e, do outro lado do plano, deverão existir vetores que descrevam empresas desonestas. Depois você poderá apresentar novos dados ao algoritmo e ele verificará em que lado do hiperplano os dados estão localizados e, com base nisso, dará uma resposta sobre a honestidade de determinada empresa.
A inferência bayesiana ingênua depende de probabilidades condicionais. É altamente provável que um determinado evento ocorra se outro evento ocorrer. Para empresas fraudadoras, calcula-se a probabilidade de um evento X1, desde que esta entidade tenha cometido fraude (evento Y). Em seguida, calcula-se a probabilidade de outro evento – X2, novamente desde que a entidade tenha cometido fraude. Em última análise, a ideia é calcular a probabilidade da conjunção de muitos eventos: X1 e X2 e X3… etc. Desde que a empresa tenha cometido a fraude primeiro. A regra de Bayes permite então calcular a probabilidade de fraude (evento Y) desde que ocorram os eventos X1, X2, .. etc. A ingenuidade no nome do algoritmo resulta do facto de se assumir que os eventos X1, são. completamente verdadeiro). Por exemplo, pode-se calcular a probabilidade de acumulações elevadas combinadas com capital de giro líquido negativo e fluxo de caixa operacional médio negativo para uma população de empresas que cometeram fraude. Então, usando a regra de Bayes e a suposição de independência a probabilidade de fraude pode ser calculada desde que esses eventos ocorram até certo ponto. A probabilidade obtida determina as chances de a empresa analisada ser uma fraude.
A análise discriminante também requer um certo número de observações para as quais a resposta é conhecida (empresas classificadas como fraudadoras ou não fraudadoras). O importante é que este método requer o uso de valores padronizados, ou seja, cada elemento do vetor de treinamento deve assumir valores do mesmo intervalo de valores – por exemplo, de menos um a mais um. Normalmente, no caso de dados financeiros, isto é conseguido dividindo o valor da demonstração financeira por algum outro elemento da demonstração financeira (ou seja, não são utilizados diretamente os dados da demonstração financeira, mas sim os chamados rácios financeiros). O algoritmo funciona de forma que seja calculado um valor médio para cada elemento do vetor de treinamento para todas as observações de uma determinada classe (no caso analisado de empresas fraudadoras e honestas) (o método assume que todos esses elementos possuem uma distribuição normal ) – separadamente para empresas fraudadoras e separadamente para empresas honestas. Então, para cada elemento do vetor que descreve uma determinada observação, é contada a distância desse elemento a cada média. Por fim, somam-se essas distâncias quadradas e avalia-se se essa distância é a menor da classe de empresas honestas ou desonestas (a qual classe uma determinada observação está mais próxima).
Afinal, as redes neurais artificiais possuem outro mecanismo de funcionamento. Um neurônio é uma equação única na qual os coeficientes das variáveis podem ser alterados. Variáveis são dados do vetor de treinamento (e depois do vetor para o qual queremos obter a resposta). Os coeficientes são completamente aleatórios no início. Os neurônios são organizados em camadas. O número de neurônios é determinado de forma bastante subjetiva, embora existam dicas diferentes sobre quantos neurônios devem ser usados dependendo de quantos elementos estão no vetor de treinamento (ou seja, quantas variáveis numéricas descrevem uma determinada empresa). A primeira camada de neurônios recebe os dados do vetor de treinamento, multiplica-os por pesos selecionados aleatoriamente e depois normalmente transforma o valor obtido de forma que os valores baixos fiquem próximos de zero e os valores altos próximos de um (por exemplo, o valor obtido é dado como argumento para a função sigmóide, que é exatamente como funciona). Os valores obtidos desta forma de todos os neurônios da camada de entrada são enviados para a segunda camada de neurônios. Esta pode ser a última camada, mas pode haver muito mais camadas. A próxima camada faz o mesmo – pega os resultados (próximos de zero ou um) de todos os neurônios da camada de entrada, multiplica-os por pesos selecionados aleatoriamente, calcula o resultado, transforma-o novamente em um valor próximo de zero ou um e envia isso ainda mais. Se a segunda camada for a última, então há tantos neurônios na última camada quanto o número de classes nas quais a rede deve classificar as observações (empresas). Quando se trata de detectar fraudes, existem duas classes (categorias) – fraudador ou honesto. Na fase de aprendizagem, o vetor final resultante não é consistente com a resposta desejada. No vetor desejado, dependendo da observação (empresa), deve haver um vetor [1,0] ou [0,1]. Enquanto isso, o estágio de aprendizagem pode ser qualquer vetor, por exemplo [0.5, 0.5] o que significa que há chances iguais de essa empresa ser honesta ou não. Mas este não é o fim do processo de aprendizagem. Agora ocorre a retropropagação. O resultado obtido, por ex. [0.5, 0.5] compara com a resposta desejada, que assim seja [1,0] (o que pode significar uma empresa honesta). A diferença é calculada [0.5, -0.5] e esse erro é usado para corrigir os pesos nos neurônios, que não são mais aleatórios após a correção. Então outra observação é passada e o resultado pode ser algo assim [0.25, 0.8]. E deveria ser [0,1] (fraude). A diferença é novamente calculada e usada para corrigir os pesos nos neurônios. Este processo é repetido inúmeras vezes, treinando a rede diversas vezes no mesmo conjunto de dados, até que finalmente a rede começa a classificar corretamente (dar respostas corretas). Aí você pode parar de treinar a rede e começar a usá-la para classificar outras empresas que não sabemos se são honestas ou não.
3. Direções para o desenvolvimento de métodos para identificar empresas desonestas
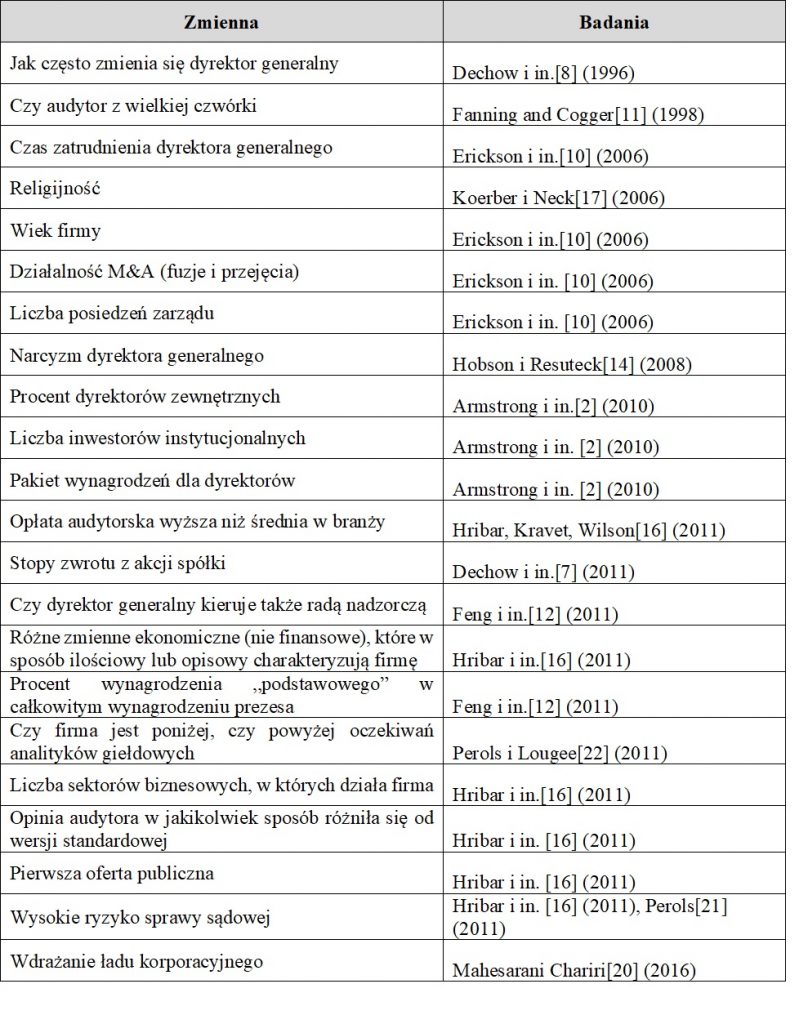
Agora que conhecemos os métodos básicos de processamento de grandes conjuntos de dados para identificar empresas desonestas, vale a pena descrever as direções em que essa pesquisa está se desenvolvendo. A Tabela 1 mostra quais dados são usados para detectar empreendedores desonestos.

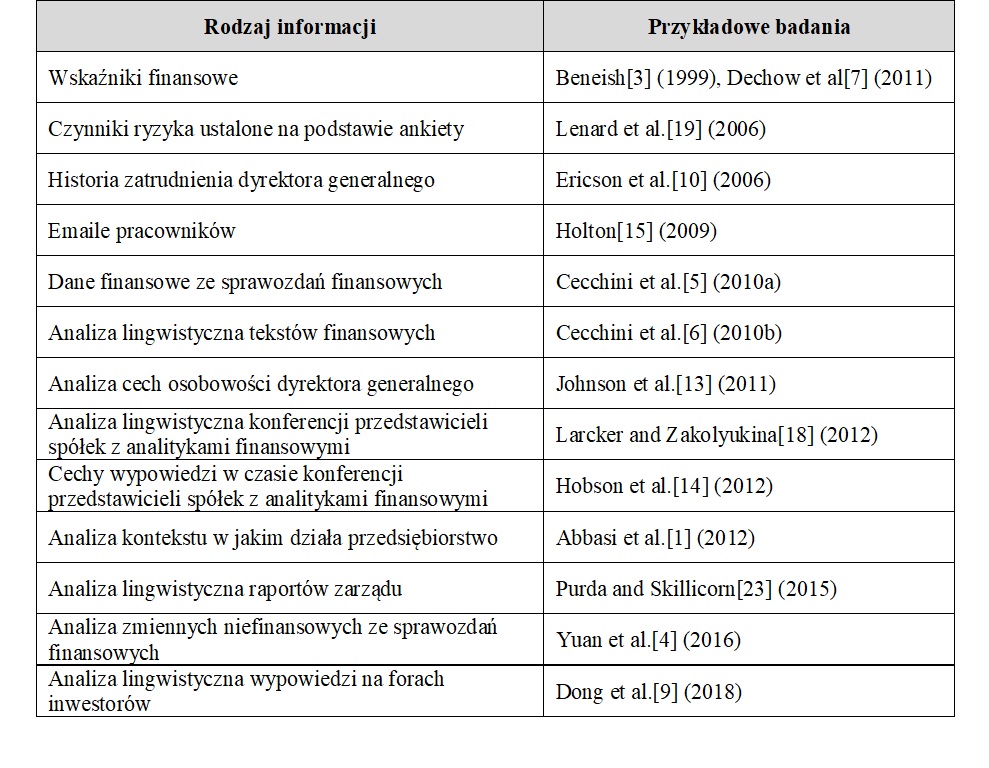
Como mostra a Tabela 1, muitos elementos ajudam a identificar empresas desonestas (na maioria dos casos, os estudos citados centraram-se na falsificação de demonstrações financeiras, mas a maioria dos crimes financeiros resultou em demonstrações financeiras que, de qualquer forma, exigiam correcção). Como você pode ver, a pesquisa começou com indicadores financeiros, mas foi rapidamente complementada com os traços de caráter e histórico de emprego do CEO, dados não financeiros, o estilo e conteúdo dos e-mails dos funcionários e relatórios de gestão e, finalmente, as opiniões dos investidores sobre o empresa.
A Tabela 2 mostra algumas variáveis específicas que foram consideradas úteis na detecção de fraudes nas demonstrações financeiras. Como você pode perceber, o porte e a reputação do auditor auxiliam na identificação dos fraudadores (os fraudadores evitam empresas de auditoria conhecidas porque há maior risco de detectar irregularidades), o tempo em que determinado CEO está no comando da empresa ( para evitar responsabilidades, diretores não confiáveis escapam por motivos fictícios), e a religiosidade de uma determinada comunidade de onde os funcionários vêm, muitas fusões e aquisições (entidades desonestas muitas vezes mascaram suas fraudes com transformações corporativas), um pequeno número de conselhos de administração reuniões por ano, o percentual de diretores externos (pessoas não relacionadas à empresa supervisionam os diretores ligados à empresa), um baixo número de investidores institucionais (que exercem controle adicional sobre as ações do conselho de administração), os resultados da empresa estão abaixo das previsões publicados por analistas externos (as empresas tentam trapacear para alcançar os resultados esperados pelo mercado), uma grande parcela de bônus de desempenho para diretores, bem como o risco e a frequência de processos judiciais (CEOs desonestos são levados a tribunal com mais frequência do que pessoas honestas), a falta de governança corporativa implementada, bem como o narcisismo do CEO.
Ao discutir publicações sobre detecção de fraudes, também é necessário mencionar a lei de Benford, que aborda a detecção de fraudes de forma diferente dos métodos descritos anteriormente. Procura-se entre os conjuntos de dados uma distribuição diferente dos números que constituem as demonstrações financeiras do que a prevista pela lei de Benford.
Quanto ao futuro da investigação sobre a utilização de big data para detetar fraudes financeiras, parece haver um interesse crescente em fatores psicológicos, incluindo os traços de caráter do CEO e a cultura organizacional numa determinada entidade. Atualmente estão sendo desenvolvidas ferramentas para identificar traços de caráter com base na fala, comportamento e textos (por exemplo, o modelo Big Five), graças às quais é possível determinar certos traços de caráter dos CEOs sem realizar testes psicológicos sobre eles. Além disso, as pesquisas utilizam cada vez mais conteúdos da Internet para analisar textos e informações sobre empresas e executivos.
É claro que também estão se desenvolvendo ferramentas para processar grandes conjuntos de dados, os algoritmos descritos no texto são métodos básicos, já existem muitas variantes (muito mais avançadas) deles e novos algoritmos estão sendo criados todos os dias.
Por fim, vale ressaltar que as ferramentas apresentadas não fornecem 100% de certeza sobre qual entidade é honesta e qual não é, mas podem processar grandes quantidades de informações de forma contínua e enviar sinais de alerta caso uma determinada entidade pareça suspeita. Outras ações e verificações devem ser realizadas por pessoas.